How can more legal help providers get more of their information & guidance into more languages?
There is a giant language access problem in legal services. So many people who need help have issues with Limited English Proficiency (LEP). Ideally, people with LEP would have equal access to legal help articles, guides, FAQs, and services in their own native languages.
But there is not enough funding, staffing, and capacity to provide robust information & services in all languages needed. Especially since each jurisdiction or organization is having to do language access on their own — it becomes a huge budget & capacity issue.
They outline various tech strategies that could increase this capacity to serve in multiple languages:
Machine Translation (like a variation of Google Translate or Microsoft Translate), in which a computer program is receiving the text, and proposing the translation. There can also be human review of the Machine Translate.
Human Translation, in which a person is proposing the translation based on their knowledge of language & the situation. This is the traditional way that language access is done. An organization hires a translation firm or interpreter to provide customized, one-off translations.
Translation Memory, in which people record their translations into a database, and then when there is a new text to be translated — they draw on this existing database for the translation. This database could be private (held by a private company or group of translators, and thus cost money to access) or open-source (held by the community and shared without cost).
This third category — of a shared database of translations and glossaries — could be a powerful solution to get to scaled, accurate language access. What if legal aid groups & legal help websites shared their multi-lingual (and plain language) translations of paragraphs, sentences, phrases, and words?
If there was a collective, open-source effort to create a Translation Memory database, this could spread the costs out among many groups. Instead of each group translating their content, they could share their past translations and allow other groups to draw from this.
This can also avoid the potential harms of a machine translation solution. In that setup, the providers are hoping that the machine (and its algorithms) can provide accurate & understandable translations. They might have a human to help review this. But the Translation Memory approach prioritizes the expert human translation from the start and then uses technology to make that approved, hand-crafted translation more accessible and replicable.
The authors of the report highlight that this shared Translation Memory approach could be valuable but costly. Here are some of their recommendations:
“The amount of time and effort that needs to be put into developing and maintaining a high-quality glossary and translation memory is non-trivial. We recommend that the Legal Services Corporation convene a group of leaders from legal services providers, plain language experts, and court leaders to adopt or discard this approach.” (page 23 of report)
They also recommend gathering a similar group of stakeholders to explore what is ethically & technically possible with combining machine translation with human review or specialized legal glossaries. Could there be an effective way to build on top of Google Translate or Microsoft Translate? It would be important to have a group of stakeholders and expert reviewers decide if this is possible and ethical.
For either a Translation Memory or Machine Translate + Human Review approach, having a shared database of glossaries is a key step. Our team at Legal Design Lab has started gathering glossaries that already exist, to start building an open-source database of legal help-oriented translations.
Please feel free to write or share if you want to work on this project with us! We hope to push language access forward with this infrastructure work, that can lay the groundwork for more accessible and scalable legal help efforts.
Especially with COVID-19 hardships, there are more renters at risk of being evicted. They’re behind on rent, they’re in an unstable economy, and they need help dealing with back-rent, fees, court cases, and the threat of homelessness.
City, state, and federal government agencies have responded with new programs. There are mediation services, legal counsel programs, rental assistance funds, navigator services, and other things — often called an ‘eviction diversion’ program.
This work has brought up the question of burdens. Especially for tenants, who are having financial hardships, many of these eviction diversion programs require tenants to do lots of things to get access to benefits.
To get rental relief, for example, it means a tenant must fill in lengthy applications, gather documents, following months-long procedures, negotiate with their landlord, and figure out eligibility formulas.
This goes back to the issue: how do we design the programs in practice — not just the overarching policies? The devil is in the details. The process often is a punishment. How do we roll out relief programs that actually achieve their intent of keeping people housed, avoiding adversarial court proceedings, and stopping harmful scarlet ‘E’ eviction judgments on people’s records? How do we make sure the programs stop spirals into poverty?
This takes us back to the question about administrative burdens. If a policy is rolled out in a high-burden way, that makes it difficult to: find out about the program, sign up for it, and follow through on it. Then many times the policy goal will be undermined. People won’t be able to use the benefit, they won’t be able to exercise their rights, and the bad outcome is going to happen anyway.
Below are some key points to take away from the Administrative Burden book— though I recommend you get a copy for yourself to dive into case studies of various government and state benefits programs, and how they’ve grappled with the politics and administration of administrative burdens.
We need to focus on citizens’ experience of government policies & programs.
The book points out that policy-making often focuses too much on the policies in the abstract and does not focus on their actual administration. There’s too much focus on the policyholder or the policymaker, and not so much on the citizen’s experience
More burdens are faced by those who have fewer resources to manage and overcome them. For many Americans, the experience of government is the experience of burden (see p. 7 of their book).
There are 3 main categories of burdens to track: Learning, Psychological, and Compliance Burdens.
We can measure how high- or low-burden a program is by looking at 3 components of a citizen’s experience:
Learning costs:
Time to learn about the program
Time to figure out if you’re eligible for it
Time to figure out what benefits you’d actually get
Time to access the program
Time to determine what conditions you need to satisfy to get it
Compliance costs:
How hard it is to assemble documents to prove you’re eligible, or what you should get
Financial and transactional costs to get services to help you get through the application — like lawyers or navigators
Travel costs to show up for interviews, file documents, get other supporting documents or fingerprints
Financial costs of fees to apply or get documents
Transactional costs to reply to communications from the program, meet deadlines, clarify requests
Psychological costs:
Overcoming stigma or embarrassment of using a service
Losing autonomy and privacy when opening one’s life to administrators evaluating them
Frustration of dealing with repetitive, unjust, and unnecessary procedures
Stress about the uncertainty of whether one can make it through the process
Sense of procedural injustice, of not having a transparent, respectful, and fair procedure
Some of these costs can be measured objectively, by gathering data about financial costs, time costs, and other quantitative measures. Others can be measured through surveys, interviews, and other design evaluations of people’s experiences.
Burdens matter to people’s use of government programs.
Burdens matter a lot. As policies and programs put more burdens on people, this affects whether people can actually get the benefits and rights that are at the heart of these policies.
And design matters to burden. This is a matter of user experience, good design, and community involvement. Good, community-centered, and creative design can shift burdens away from citizens and on to the government. How can we shift burdens to those with more resources to bear them? That’s most often away from citizens individually.
Design can help us measure burdens as we are creating new programs and services, and then evaluate them in their pilot stages. Are people being frustrated? Are they dropping out from onerous tasks? Are they becoming alienated from government services because of how burdensome a program is? We can use design techniques of user testing, UX evaluations, and human-centered evaluation to measure these burdens and create new strategies to repair them.
Every public service should have good citizen experience (and burden reduction) at its core.
As groups are making and evaluating new programs, they should be aware of citizens’ experiences and burdens. This means having these principles at the core of their work:
The program should be designed to be simple
Processes should be as accessible as possible
The program should be respectful of the people they encounter, and dignity should be at the core
Design can again help here. This can be done through User Personas, User Journey Maps, trackers of where people are failing or falling off, surveys about stress and procedural justice, and measurements of wait times and other objective measures of burdens.
We can create replicable strategies to lessen burdens and improve citizens’ experience.
How do we make Administrative Burdens & Citizen’s Experience part of front-line policymaking and service delivery?
The book points to a few directions:
Training policy managers & on-the-ground administrators in the importance of the citizens’ experience, these 3 kinds of burdens, and the importance of good service design. There also needs to be explicit training in equity & burdens — about whether people from certain demographic groups are being asked for more evidence, put through more process, and asked to shoulder more burdens.
Instituting more testing of burdens before and after a program rolls out. If we measure it, we’ll optimize for it. This means gathering data on the learning, compliance, and psychological costs — -through intentional data-tracking, running of surveys, mapping of user experiences and drop-offs, etc.
Deploying burden-reducing strategies that can reduce these learning, compliance, and psychological costs. Some of these burden-reducing strategies include the following. Many of them draw on nudge/behavioral heuristics literature.
Burden-reducing strategies for public programs
Limit eligibility criteria. Cut out unnecessary or overly burdensome ‘means tests’ that make people prove they are eligible based on various income and financial assessments
Limit the amount of choices, reduce cognitive demands, and label what the most common choice is.
Invest in community-based outreach, to make it easier to find out about the program and learn other people’s stories of it.
Label and brand programs in positive terms, that reduce stigma, embarrassment, and moralizing.
Auto-enroll people, presume they are eligible and cut out tasks they must do to get access to the program.
Figure out which party is well-resourced, and pass high-burden tasks around document uploads and financial accounting to them.
Possibly do cross-overs between programs, integrating data from other programs so there’s no need to fill in forms with information the government already has, or upload new documentation.
Open Question: does lowering burdens on citizens mean trading off privacy?
One question to balance the burden discussion with is around people’s privacy, and control over their own data. Many strategies around lowering burdens mean collecting and connecting data together.
Especially if it is poorer people applying for these programs and needing ‘burden-reduction strategies’ — it’s likely to be their data that is being handed off between programs in order to make it easier and quicker to use a service.
Does reducing burdens lead to a reduction in privacy from the government? What is the balance between an all-knowing government, in which agencies are passing off information about a person back and forth — and an easy-to-use government that is significantly easier to access? There’s a huge need for design sessions, technical solutions, and policy work around this trade-off, of low-burden government services that also protect vulnerable people’s privacy.
Last night at my Public Interest Tech Case Studies class, our guest speaker was Dr. Tina Hernandez-Boussard of Stanford School of Medicine. She is a multi-hyphenate: doctor, epidemiologist, and researcher who works on how AI algorithms are being developed and deployed in health care. One of her lines of work is looking at whether the AI applications being deployed in medical work are not only technically robust, but also ethical, human-centered, and socially just.
The promise of AI in medicine is huge: if researchers, machine learning experts, and clinicians can draw on all of the past data of patients, symptoms, treatments, and outcomes — they may be able to offer better, quicker, more intelligent help to people who are struggling with illness.
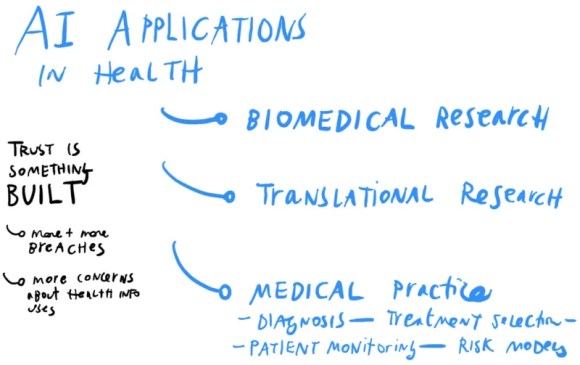
Dr. Hernandez-Boussard identified 3 main tracks that medical professionals are using AI for. These may be analogous to legal tracks that are beginning, or may begin soon, for legal help & AI. They are:
improving biomedical research (like in surfacing important findings from researchers, and links between studies),
doing translational research (like in how the genome affects diseases and outcomes), and
improving medical practice (like in how diseases are diagnosed, treatments are selected, patients are monitored, and risk models of disease/outcomes are built)
What potential is there for AI for Access to Justice?
This third track is perhaps the most exciting one for those of us focused on access to justice. What if we could better spot people’s problems (diagnose them), figure out what path of legal action is best for them (treat them, or have them treat themselves), and determine if their disputes are resolved (monitor them)?
Our Legal Design Lab work with Suffolk LIT Lab is already working the first thread, of spotting people’s problems through AI. We had collaborated on building Learned Hands, to train machine learning models to identify legal issues in people’s social media posts. That’s led to Suffolk LIT Lab’s SPOT classifier, that is getting increasingly accurate in spotting people’s issues from their sentences or paragraphs of text.
This medical scoping of clinical AI uses could inform future threads, aside from issue-spotting, for legal aid groups, courts, and other groups who serve the public:
Legal Treatment AI: Can we build tools that predict possible outcomes for a person who is facing a few different paths, regarding how to resolve their dispute or issue? Like a tenant who is having problems with a landlord making timely repairs: should they call an inspector, file for rent escrow, try to break their lease, use a dispute resolution platform, or do nothing? What would be the time, costs, and outcomes involved with those different paths? Many times people seek out others’ stories to get to those data-points. What has happened when other people take those steps? AI might be able to supplement these stories with more quantitative data about risks and predicted outcomes.
Problem Monitoring AI: Can we build tools that follow up on a person, after they have interacted with legal aid, courts, or other government institutions? Did their problem get resolved? Did it spiral into a bigger ball of problems?
The need for community design + ethical principles in AI development
That said, with the promise of these medical-inspired threads of legal help AI — Dr. Hernandez-Boussard warned of the importance of careful design of the AI’s purpose, data sources, and roll-out.
The danger is that AI-specialists develop new algorithms simply because it is possible to do so with available data sets. They may not think through whether this new tool (and the data it’s based on) is representative of the general population and its diverse demographics. They may not think whether clinicians would actually use this algorithm — whether it solves a real problem. And they may not think about unexpected harms or unequal benefits it might result in, for the patient.
This shows up with algorithms that detect heart failure in men, but don’t work at all for women. This is because the data the algorithms were trained on, is based on trials populated mainly by white men. Their symptoms for heart attacks are markedly different from women’s symptoms. So the model doesn’t detect women’s risks accurately, and may result in women not getting the prioritized care or appropriate treatment. A similar story is developing in regard to skin cancer screenings, in which the dataset training the AI is mainly from fair-skinned patients. Thus, the tool likely won’t be as effective for screening cancer in darker-skinned patients.
AI built on non-representative data, or rolled out with too much trust in its predictions, may result in poor care, bad outcomes for unrepresented groups, and less overall trust in the health system (and the AI).
Dr. Hernandez-Boussard is working on a better framework to think through the development of AI for clinical care.
Stakeholder Involvement in scoping the AI project, setting standards, and limits
Data cleaning, quality-checking, and pre-processing — to make sure the data is as recent, accurate, representative, secure, etc. as possible
Development of tech and testing of its fairness — to make sure that it is making accurate predictions, especially across protected classes of gender, race, etc.
Rolling out the AI to be transparent and usable — so that practitioners don’t over-rely on it, use it for problems it wasn’t meant to solve, and to make it comprehensible and usable to patients and their care teams
This involves early, deep stakeholder involvement. In this phase, there are critical discussions about whether AI is needed at all, what important questions it can answer, and whether clinicians and patients would actually use it on the ground.
Legal design is also essential in the fourth phase of development: how is the AI rolled out to people on the ground who should be using it to make decisions. Do they know its limits, its standards, and its sources? How can they be sure not to over-rely on it, yet still build trust in what it is able to do? And how do they help overwhelmed patients make sense of its predictions, risk scores, and lists of percentages and possible outcomes?
Are you interested in learning more about ethical AI in healthcare, and how it might be used in other fields like legal services? Check out these upcoming events and online courses:
Its description: With artificial intelligence applications proliferating throughout the healthcare system, stakeholders are faced with both opportunities and challenges of these evolving technologies. This course explores the principles of AI deployment in healthcare and the framework used to evaluate downstream effects of AI healthcare solutions.
Its summary: Artificial intelligence has the potential to transform healthcare, driving innovations, efficiencies, and improvements in patient care. But, this powerful technology also comes with a unique set of ethical and safety challenges. So, how can AI be integrated into healthcare in a way that maximizes its potential while also protecting patient safety and privacy?
In this session faculty from the Stanford AI in Healthcare specialization will discuss the challenges and opportunities involved in bringing AI into the clinic, safely and ethically, as well as its impact on the doctor-patient relationship. They will also outline a framework for analyzing the utility of machine learning models in healthcare and will describe how the US healthcare system impacts strategies for acquiring data to power machine learning algorithms.
The COVID-10 pandemic has precipitated much national chaos and confusion with regard to the legal process of evictions. Several local governments and courts have been adjusting their policies to accommodate the current catastrophe, such as by placing temporary moratoriums on evictions or relaxing payment deadlines for tenants.
In response to this housing crisis, we have been working as part of the Stanford Legal Design Lab to build a Legal FAQs platform providing jurisdiction-specific eviction information on a local, state, and federal level. Our primary task as summer interns these past few months has involved achieving 50-state coverage on legal, easily understandable content for people facing eviction lawsuits.
Based on the skills and knowledge we have acquired while working on the eviction platform, we have written below an easy guide to creating user friendly FAQs.
1. USING SIMPLE LANGUAGE
One of the most important things to keep in mind when creating user friendly FAQs is your audience. Who are you writing this for? It’s very easy to lose ourselves in legalese or whatever technical jargon we’re familiar with, to assume that we’re all on the same page, and for our audience to be left behind. As silly and Elementary-esque as it sounds, sometimes it helps to read what you’re writing out loud. If it sounds too complicated or verbose, you know that you need to go back and edit to try to keep it simple, both in language and conceptually. Keeping the language basic and easy to understand ensures that your users, no matter their background, can always follow along.
2. KEEPING CONSISTENT WORDING
On this same line of thought, it’s important to have plain language consistency. One way to do this is by creating an overall general template that you can use for each portion of your FAQs, and then to fill in the pertinent information as you go through answering the specific questions. This way the wording will be consistent all throughout.
3. REVIEWING WITH PARTNER
Be sure to review your work. It’s a great idea to work in a team or with a partner; this way you can review each other’s work to make sure that you are both using plain language, and using a template ensures that you both are using consistent language. You can catch things your partner might have overlooked or missed and vice versa.
4. TRACKING SOURCES
Another tip for creating FAQs is to keep a list of sources as you conduct your own research. Our team worked on creating FAQs for all 50 states. Starting was very difficult — not knowing how to navigate all the legal codes and research out there made it slow going, but once you begin to recognize sources that you can use or even certain terms or phrases to search, it becomes much easier. And so keeping a list of the sources or phrases you use to research will help you as you curate FAQs.
5. REACHING OUT TO EXPERTS
It’s also extremely important to prevent people from finding the wrong information. You can do this by reaching out to volunteers, professionals in whatever field you’re creating FAQs for, and asking them to review your work and ensure the accuracy of your answers. In our case, if even one of our answers is incorrect, and people read our FAQs and think that they have more time to answer an eviction suit than they really do, it can have serious consequences. This is why it’s very important to verify your work as you go along.
FINAL WORDS:
We at the Legal Design Lab used this process to successfully develop eviction FAQs and anyone can follow this guide to create their own set of user-friendly FAQs. One of the biggest takeaways from this article is to be mindful of your audience — FAQs packed with jargon aren’t useful to anyone, so make sure to use simple language! Through these five easy steps, — using simple language, keeping wording consistent, reviewing your work, tracking your sources, and reaching out to experts, you’ll be able to create accessible and easy to understand FAQs while maintaining verified correct information.
In the era of COVID, public interest organizations from legal aid societies to public health departments have never been busier while many students have never had more free time. So, too, our civic need for effective social problem-solving has never been greater. What better time to launch a curated platform for social problem-solving and civic technology?
What if there was an online exchange and information-sharing forum, the Public Interest Project Hub (PIP Hub), that would enable students and public interest organizations to connect to share ideas and coordinate projects to address civic needs.
Public interest organizations or citizens with problems who understand public and organizational needs could add project proposals to the Hub. These ideas and proposals might range from a client intake system that facilitates real-time statistical analysis to a know-your-rights app that helps people understand regional laws and advocate for themselves, or a hundred other creative ways to address or mitigate collective problems. Students with relevant policy, design, and technological skills could then connect with the organization in a volunteer or contracted capacity to develop a project plan that leads to a research report, tech tool, website, or another outcome that helps scope or address the issue at hand.
PIP Hub, diagrammed
GitHub has been wildly successful in allowing people from across the world to collaborate on technical projects such as Bootstrap and JQuery; but, without guaranteed and actively managed student and community/organizational participants, similar spaces for public interest technology have not emerged. This is a shame as there are likely many front-line organizations who have unmet technical needs and many students who would be excited to support them in developing solutions.
Think of PIP Hub as a forum combining features from Google Drive and GitHub. The drive would be the external-facing system that students and organizations could use to connect with each other. It would contain a project idea intake form and a Google sheet listing open projects that students could either apply to or just start working on. It could also contain white papers describing organizational and community needs; completed student research on public policy and/or social problem-solving issues; and folders that link to completed or ongoing social problem projects on GitHub. The PIP Hub would facilitate the collaborative development of technical projects. It would also make it easy to build open-source projects available to a broad community of developers and users.
Students who have worked on policy/civic tech projects but who have since stepped away from their work could also benefit from the hub. Many project-based courses require students to research and prototype projects, but after the term ends most of those projects never move forward. The next year another group of bright-eyed students enters the same course only to repeat the cycle. Students who worked on policy proposals or civic tech projects could leave their projects in the drive and then allow students who take a similar course, or are just interested in the project, to pick up where they left off and move the project further toward real-world use. Public interest organizations could also view these projects, provide feedback, and write proposals for a group of students to build a tool based on a student prototype.
Some public interest organizations may hesitate to engage with PIP Hub, pointing out their need to own the data they create and control the technology they rely on. Yet, the counterpoint is a pernicious trend in civic technology with proprietary software that privatizes public data, prevents community members from understanding a technology’s impact, and creates barriers for widespread adoption. To ensure ethical and effective design, all work-products that emerge from the hub should be open source or licensed through Creative Commons. If necessary for their mission, public interest organizations should be able to request that work products be closed source.
In sum, the PIP Hub could facilitate an innovation ecosystem grounded in civic engagement that would connect public interest organizations with unmet needs to students who are seeking ways to develop their skills in policy research and/or civic technology. It could also connect students who have started policy/civic tech projects to others looking to carry them forward.
To ensure a successful innovation ecosystem, PIP Hub staff would need to perform several administrative and constructive functions. They would need to publicize and solicit engagement for the drive from public service organizations, students, and professors. They could also structure the terms on which the work would be done and facilitate project sustainability by providing students with either course credit or grant funding. Once projects are completed, the Hub could publicize the products to similar organizations that could benefit from their use. Staff could also connect students and organizations to professors or foundations who could advise or fund projects. Lastly, they could organize and index documents so that content is easily searchable. On the Google drive, this could mean imposing a standard format on the tracking sheet and grouping projects displayed for external observation by issue area to be most accessible for partner organizations. On Github this could mean managing permissions and ensuring that each project has a README file containing a comprehensive summary of the project. Financing for the PIP Hub could be provided by such groups as the Public Interest Technology University Network or the philanthropies behind it. University programs and departments could pay small dues to give their students access, thereby enabling cross-university partnerships and team experiences for their students. Public interest organizations could join as members. Corporations could sponsor the hub as donors. Throughout, the Hub would retain its independence and neutrality to enable civic organizations, community members, and students to partner freely on projects. It may also be advantageous to pilot several different hubs with different funding and administrative models based out of different research universities. After a trial period, the hubs could compare, adopt best practices, or merge into a unified system.
In short, the PIP Hub would contribute to a world where communities can join together in collective problem solving to find sustainable solutions to public problems. It would facilitate the distributed creation of high-quality research and technical tools that public interest organizations could use at low-no cost. It could help communities share information and find collective solutions to problems they identify. It could serve as a training ground for a generation of students interested in applying analytical and technical methods to societal problems.
Michael Swerdlow is a recent Stanford graduate and admit to Columbia Law School. If any organizations are interested in creating their own PIP Hub feel free to reach out. Contact: mswerd@stanford.edu
For those of you who have missed the news, OpenAI trained a model (ChatGPT) that answers queries in a conversational manner: it responds to follow-up questions, corrects mistakes and challenges/rejects inappropriate requests.
Is AI Chat the New Google Search?
I found people raving about this new chat model. One particular tweet really stood out me:
ChatGPT seems like such an amazing new way to search for information online. I was eager to test it out for myself, in particular for one of my favorite research interests: online legal information.
What would AI Chat Mean for Legal Help Info?
As you all know by now, one of our aims at the Lab is to connect users to jurisdiction and legal issue-specific information that is up-to-date and freely accessible (so not hidden behind paywalls). We are working towards a reality where Google and other search engines provide snippets and legal knowledge panels, similar to what they do with health knowledge panels. As most people search for legal information online, providing users with jurisdiction and issue-specific information would ensure that we increase legal capability, access to justice and that we empower users during their legal journey.
Image rendering by Margaret Hagan
Legal Search Results Are Often Low Quality
Compared to that vision of a clear, authoritative search results page, we are still not there.
The top results on search engine result pages are not jurisdiction-specific. They direct users to websites with most of their relevant content behind paywalls. Or, most often, search engines send people to websites with content-farmed generic information that is technically ‘correct’ but not actionable. These generic short articles don’t provide the user with good quality legal information that they need to proceed in their legal journey.
In the worst-case scenario, search engine results can be outright misleading. Take this results page for a free counsel query, that’s searching for a free lawyer for an eviction lawsuit.
A person facing eviction in San Francisco is guaranteed a free lawyer under the new “Right to Counsel” as of Summer 2019. But a Google Search for “free lawyer for eviction SF” directs them to a Knowledge panel from a commercial law firm.
What do search engines show to landlords versus tenants?
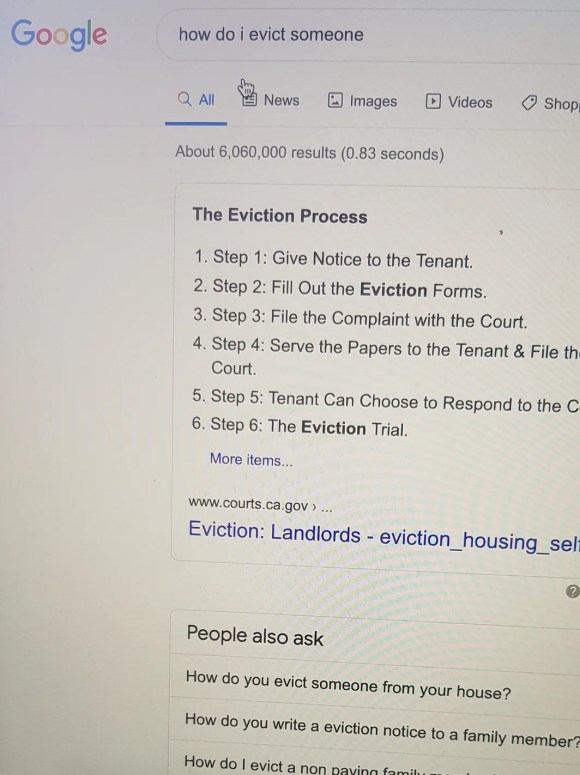
I have also recently observed that there is not an equal playing field when it comes to search queries from tenants and landlords.
Compare these two images and queries. One is from the perspective of a tenant, looking for information about eviction. It has no snippets or knowledge panels and the second and third result on the page are websites with generic information. The other image is a query from the perspective of a landlord. The landlord receives a legal snippet from the California Court’s website.
These user-friendly snippets should be available for all parties to ensure there is an equal playing field. Why is the search engine showing a clear checklist to one party, but not another?
So far, I have not heard a single argument why this could not be possible.
Can AI Chat do better than Google Search?
You can therefore understand my excitement when I saw the ChatGPT results. What would happen if I asked the chat model my usual eviction queries?
The information provided by ChatGPT is correct. I also applaud the plain language. Unfortunately, the information is too generic to really increase legal capability and empower users on their legal journey. So let’s see what happens when I ask a follow-up question:
Although the bullet point list is excellent and easy to digest, the information that is provided is too generic to really make a user understand the next steps.
Obviously, at this point, I did not input a jurisdiction in my query. Most users would not mention their location in a query and I was secretly hoping that ChatGPT would prompt me to do so. It did not and I definitely think there is more ground to be gained on this front.
Again, the information is not wrong, but I was just fervently hoping that ChatGPT would actually mention my rights as a tenant in Palo Alto.
I was also curious to see if there would be differences in how queries from landlords would be treated, so I tried out some queries.
My first query was without and the follow-up question was with a location. Queries without location are too generic to be truly useful for users searching for online legal information. The queries with location for landlords are slightly less generic than for tenants. Again, I wonder where this discrepancy stems from? Both tenants as well as landlords need access to good quality legal information. There needs to be an equal playing field for both parties.
ChatGPT could gain so much ground by delving into the world of legal information. Even small tweaks such as prompting users to input their location if they ask a legal query would already be a massive win. It would push access to justice into another realm if, in the future, we could have ChatGPT walk users through the process of their legal query and provide specific, high-quality legal information.
There is a High-Quality Supply of Legal Info Online. It’s Just not being shown by platforms.
Jurisdiction and legal issue-specific, high-quality legal information already exists online. Courts, legal aid organizations, and others have been working tirelessly to create content for users with a legal query.
Unfortunately, these pages cannot compete with commercial websites in search engine page rankings. This is a huge loss for everyone involved, from the legal community to the tech companies.
Search engine pages are the starting point of people’s legal journeys. Millions of people use the Internet before they consult legal professionals. If search engine pages make the first step on this legal journey haphazard or outright dangerous in case of misleading information, it not only affects an individual’s legal journey but also erodes trust in the legal system in the long-term.
Legal Help Groups Need To Work with Online Platforms
Legal professionals, researchers, and tech companies need to actively work together to make sure everyone can access good quality online legal information. Please do not hesitate to reach out if you want to collaborate on this topic:
P.S. What About the Legal Images?
By the way, as for DALL-E (the AI image generator), I had hoped that DALL-E would be a way for legal aid organizations and courts to stop using stock images.
User research indicates that stock images come across as impersonal, especially when one is searching for information about stressful and traumatic legal issues.
At the Lab we always advise organizations to put time and effort into creating customized imagery. After playing around with DALL-E and eviction-related keywords, I’m going to hold off on that recommendation for the time being, as I do not think that melting AI faces would help make legal information websites feel more welcoming.
This is what AI comes up with for eviction imagery.
Digital Legal Needs analysis of an online legal clinic to predict seasonal trends in people’s legal needs
What can we learn from people’s legal questions online? Especially, how can we use this data to serve people in better ways?
Stanford Legal Design Lab collaborated with the American Bar Association to analyze ABA Free Legal Answers. Free Legal Answers is an online legal clinic through which low-income individuals get answers to civil legal questions from lawyers, completely free of charge.
The Lab has analyzed people’s questions from the clinic’s data from between 2012 to 2019. During this period, there were tens of thousands of questions asked across the many states that Free Legal Answers is offered. Each of the questions was self-labeled by the user (or, by the platform administrator) with the broad legal category it belonged to — like Family, Housing, Veterans, Employment, or Consumer.
Free Legal Answers is an online clinic, where people who income-qualify can ask questions about their civil legal problem & get free assistance from a licensed lawyer. See more: https://abafreelegalanswers.org/
Digital legal needs analysis of the clinic’s questionshas helped us identify what trends exist in people’s use of the Free Legal Answers clinic and what needs they are coming to the clinic to get help with.
What can we do with this digital legal needs analysis? It helps the ABA and other legal service providers to develop smarter tools and strategies to address clients’ needs.
Our first focus has been on seasonal trends throughout a calendar year:
When should legal services hold public education campaigns about legal needs?
When should they conduct marketing and buy ads?
When should they be recruiting volunteers to serve more people?
After a natural disaster, when are people seeking help?
Our second focus has been on getting the messaging right. What words should providers use in outreach and advertisements, to resonate with the target audience?
What phrases do people use to describe their legal needs?
This report has recommendations for the ABA and other legal services groups about how to use data to best communicate legal information, mitigate the effects of legal problems, and recruit attorneys to assist. Digital legal needs analysis has the potential to predict legal problems before they occur, thereby enabling advocates to pre-empt access-to-justice challenges at the outset.
1: General Outreach for Legal Services in the Late Summer to Early Fall
Generally, the heaviest usage of Free Legal Answers occurs from August to October. This holds true across various states, for several years, and across most legal issue areas.
Figure 1: This chart illustrates the usage of the 7 legal issue categories on ABA Free Legal Answers between 2012–2019
During these months, if there was wider outreach (through marketing campaigns, events, and other channels), then a wider group of people — who might also be experiencing a spike in legal needs during these months, but who aren’t aware of legal help services — may become aware of Free Legal Answers.
2: Seasonal Issue-Area Targeted Outreach
During known seasonal spikes for particular issue areas, there might be outreach targeting these specific needs.
For example,
Questions related to education problems peaked in February-March and August.
Income maintenance questions peaked between February and April.
Work and employment questions peaked during October to November.
Sexual assault questions peaked in July and October (and dropped significantly in February and March).
These seasonal peaks can guide marketing and event outreach, in which the legal services community coordinates issue-area campaigns to engage a wider group of people who potentially have these needs during these times. It might be through special awareness months, series of clinics and know-your-rights events, advertisement purchases, news media collaborations, or events with community partners.
Figure 2: This yearly calendar provides an overview of the times of year when people may be seeking help for certain legal issues, and what legal service organizations might do to prepare for them.
3: Preventative Public Education During Months Before Spikes
Data-driven action should not only be taken during the month in which the trend or decline of a legal issue takes place. Data analysis can also be used to take preventative action.
For example, if family issues are spiking in late summer and early autumn, then there should be proactive public education campaigns in the preceding months that give preventative information about family law problems. These preventative resources should come at the key time when people are beginning to have questions or issues, but they have not yet escalated.
4: Seasonal and Issue Specific — Volunteer Recruitment
Data provides an insight into the peak times on the platform. This might mean that during some months more volunteer lawyers and students are needed.
Based on the data analysis, predictions can be made on when to start recruiting and training volunteers to deal with the high volume of requests. Recruitment decisions can also be made when data indicates that certain issues are high in demand.
For example, income maintenance questions peak between February and April. During these months volunteers with this issue area specialization should be recruited.
5: Post-Disaster Legal Help Sequencing
Legal service groups can be prepared to serve the particular sequence of legal needs that emerge after a flood, hurricane, wildfire, earthquake, mass shooting, pandemic, or another disaster.
This means distributing particular resources and ensuring there is service capacity for issue areas in the immediate weeks after the disaster hits, and then in the long-tail of months and years afterwards.
6: User Keyword-based Outreach
When legal service organizations are doing outreach to engage a wider public in preventative education or services, they can make use of keywords that people use when talking about particular legal problems.
This approach can help inform how outreach is phrased, what adwords are bought, and how materials are presented. Rather than communicating in legal categories (like housing law, landlord-tenant issues, or unlawful detainers), the outreach can instead reflect the most common phrases that people use for an issue.
For example, our Reddit keyword modeling research, drawn from posts on r/legaladvice, illustrated the following common phrases that people use:
Housing legal needs phrases
There were several housing categories in our Reddit keyword modeling research. One category focused on tenant-landlord relationships.
The most commonly used phrases for this category were: security deposit, deductions, return security, 21 days, 45 days, withheld, wear tear, normal wear, written notice, itemized, certified letter, forwarding address, notice given, days prior, carpet cleaning, cleaning fee, walkthrough, tenant shell, lessor, court, small claims, manager, management, landlord and tenant.
Work and employment legal needs phrases
There were several employment categories in our Reddit keyword modeling research. One of these categories focused on employment contracts.
The most commonly used phrases for this category were: contract, employment, signed, shall, offer, sign, employer, current employer, job offer, clause, termination, severance, non compete, notice, unemployment benefits, offer letter, week notice, resignation, written notice, new contract, enforceable, bonus and commission.
Family legal needs phrases
There were several employment categories in our Reddit keyword modeling research. One of these categories is focused on assault, violence and abuse in the home. The most commonly used phrases for this category were: police, charges, called, help, family, friends, sister, brother, home, tell, told, neighbor, mom, mother, scared, happened, threatened, sexual, sex, sexual, violence, kill, assault, physically, rape, screaming, yelling, pictures, media, door, room, cat, dogs, inside, bathroom, animal, gun, ill, suicide, rape, stalking, weed, meds, drunk, eye, and face.
Our Lab is continuing to work on using the data to improve the services & experiences for people seeking legal help online. The ABA Free Legal Answers team, Baylor Law School, and our Lab have been leading a project to identify and answer FAQs in the highest volume legal need areas.
These FAQs can be given to people after they ask a question, and are awaiting a response from an attorney. The data helps us spot the most common questions, and also phrase them in a way that makes sense to a person who is not a lawyer.
For more information about ABA Free Legal Answers, see Ambar.org/fla or contact Tali Albukerk at tali.albukerk [at] americanbar.org.
This is part of ongoing work at both the Legal Design Lab and CodeX. Our Lab has been working on improving contracts, terms of service, and other legal text that people must grapple with to protect themselves. We’ve taught classes at the law school and d.school on these topics & have documentation of what we’ve been learning.
CodeX has made computable contracts a central theme for the coming years. Their Insurance Initiative is pioneering new ways to make contracts machine-readable, create a standard language for contracts, and pilot new ways to improve contracts in insurance use cases.
Our goal with the course — and ongoing design work with computable contracts — is to make sure that as this new technology develops, it’s done with real people’s concerns, frustrations, capacity, and dignity at the center.
Of all the ways we can improve the infrastructure of contracts and how they are deployed, what will people be able to use — and to get them better insurance and health care?
Key Opportunities for Human-Centered Computable Contracts
Before diving into the details of the class, our user interviews, and our initial brainstorms, it’s worth jumping to some of the big takeaways. What should people working on improving contract experiences be focused on, to truly solve people’s fundamental problems?
“Let Me Know What You Know”: Tools to Address Information Asymmetry
The most central problem in the consumer-insurance provider-health provider relationship is information asymmetry. Even if you are a power-user, who is doing everything you can to figure out how to be wise when it comes to saving money and getting the necessary care — you still cannot find out what things actually cost until after the event has happened, choices about care have been taken, and claims have been filed.
People, especially more proactive users, want tools that start to balance out this knowledge. They want tools to help them
know before purchasing a policy how it will play out in key situations they expect might happen (a back surgery, an urgent care visit, a pregnancy, disability support, etc…)
know what different claim codes will be covered or not, before they actually go for service from a certain medical provider and with certain claims being raised
This could be in the form of chatbots, price predictors, shopping quizzes, or even more intelligent phone calls with customer service. But they want to know what the customer service reps at the insurance companies and health care providers know. What are the real prices of things? What are the possible ways a messy life problem might be encoded into claim numbers? And what are the strategic decisions a person can make before they get encoded into a certain claim path & have to deal with the bills that might follow.
Computable contracts, paired with open data sources from health providers or insurance companies, can be a foundation for these tools to address information asymmetries.
“Give Me Something I Can Rely On”: Tools that Give Ground Truth & With Assurances
Information tools are not enough. Many consumers have been burned by previous interactions with insurance or health providers, where they have been given information by a customer service rep or policy — and then found out later that it was not reliable. A bill ended up being way more. A procedure wasn’t actually covered. The provider wasn’t actually in the covered network.
More proactive consumers try to get to a ‘ground truth’ right now by triangulating extensive research. They call the insurance company’s customer service reps multiple times, to speak to multiple people, and compare their responses to find out what they can rely on. They go to Reddit boards, Facebook groups, and chat with friends to find other people who may have ‘ground truth’ experiences that are comparable. What will actually happen to me? Who can I trust to tell me the truth?
Recent policy changes in the US may let consumers contest bills that turn out to be surprisingly high. Another direction would be for providers to have to honor the price that a person receives from a computable contract-powered tool.
A person, before they use a service or buy a policy, can use an intelligent tool to get a prediction of the out-of-pocket cost and claim coverage for a certain service. They can save this and rely upon it. If they do use this service, and the price turns out to be higher or the claim is denied, then they can show the prediction to contest the decision and protect themselves.
Computable contracts tools’ value will be in how reliable and binding they are. They need to give some guarantees to the consumer to get to the fundamental mistrust and betrayal that most consumers have toward their insurance companies.
“Why Does This Have to Be So Crummy”: Design a Claims Process that is Empathetic and Supportive
When people try to make use of their insurance policies, often the process is murky, painful, and stressful. The consumer is often the last to know what is happening, as the other 2 parties — the insurance provider and health provider — are in communication making important decisions.
Plus there are opaque and overwhelming statements that come to the consumer, about possible amounts they may owe, claim codes about what services they have used, and ultimately an amount due as soon as possible, or a collections company might start hounding them.
The user does not feel like she is in control, or has a sense of dignity. There is no delight in the claims-making or -processing journey. People feel like no one is on their side — and the other 2 parties seem to be ganging up on them, to try to push their companies’ financial responsibilities onto the person with the least power and money. People want an advocate, someone on their side.
Computable contracts, mixed with new service design-oriented offerings, could help transform this process. What if there was more transparency & sense of control for the user before, during, and after the claims process? What if they felt that the price they were paying was agreeable, worthwhile, and acceptable — because they had more of a choice in deciding to make use of the service at this price, and because they have tools to contest it when it is too high.
Even more, insurance providers could think about proactively giving service maps — -with expected claims, services, and costs, to people who are on a certain medical journey. Whether a person is starting off with a pregnancy, fighting a disease, or treating a disability, the data about past claims and costs could be used to provide sample maps to consumers about what other people have done to make use of medical services in wise, financially affordable ways. The insurance provider can use its knowledge of so many consumers’ journeys to help a person plan out their use of services and risks they will take, to make sure they are doing it as wisely as possible.
The Class’s Basics
Our joint class Human-Centered Computable Contracts was taught as a policy lab, meaning we were able to do project-based work in partnership with a public interest group. In this case, our partner was the federal government group CCIIO (pronounced suh-sigh-oh), the Center for Consumer Information & Insurance Oversight. It is part of the US Centers for Medicare and Medicaid Services.
During the 9-week class, we had two main phases: exploratory interviews with people about their health care insurance contract experiences, and then prototyping and testing possible interventions (including around computable contracts) with people. Our goal was to learn more about whether and how computable contracts could benefit people in their health care and insurance activities.
We taught the students many service design techniques to make sense of the interviews and research: journey mapping, persona creation, and user story-telling. In addition, we did creative brainstorming through different structured activities. We drew from formal presentations on what computable contracts are — to then think through: how exactly could we make them useful to the people we’ve spoken with? The students made concept posters and tested the top five concepts with users to get their feedback.
We had a terrific, tight group of students who came from a mix of backgrounds. We had law students, computer scientists, and public policy students. Some had past experience as practicing lawyers, health care policy analysts, and technologists.
User Research to understand people’s journeys through health insurance
We began the class with the simple question: What are people’s experiences with health insurance contracts? And we also held on to a second question (more for the second half of our class): What are key opportunities for Computable Contracts to improve experiences & outcomes in health insurance?
We took a design approach to answer these questions. That meant talking to many stakeholders, including people who have been consumers and users of health insurance, as well as experts. During the quarter, the students and teaching team conducted 10 user experience interviews and 6 user testing interviews.
The teaching team recruited interviewees through social media advertisements and an intake screener. They signed up from around the country, and with different economic and educational backgrounds. Each interviewee had some experience with health insurance — some had been through multiple plans, others had their first insurance purchase this year. Each interviewee was interviewed over Zoom for between 20 and 40 minutes and compensated with a $40 gift certificate.
In the user experience interviews, we asked insurees to discuss their best and worst experiences with health insurance. We particularly asked users to discuss their experiences shopping for health insurance, making claims, and understanding coverage or prices. In the user testing interviews, we asked users to share their opinions regarding five different ideas about ways to help someone with their health insurance.
Insight into user experience was also shared in presentations and feedback sessions by Rogelyn McLean (Senior Advisor at the Center for Consumer Information & Insurance Oversight), Gary Cohen (former Vice President of Government Affairs at Blue Shield of California), Clara Bove (Researcher at AXA), Raphael Ancellin (Lead Product Manager at AXA), Pierre-Loic Doulcet (Computational Contract Engineer at AXA), and Michael Genesereth (Research Director of CodeX).
In addition, the team looked at past user research into people’s experiences with health care and insurance. The Enroll UX 2014 efforts, around the rollout of the Affordable Care Act, has very useful documentation of their user research into health care insurance customers.
What We Found in User Interviews
From our interviews, we learned that one size does not fit all when it comes to user needs and preferences.
Some of the key themes we heard, about how health insurance contracts & services could be improved
Insurees’ needs and behaviors are influenced by their level of health insurance literacy and proactivity in seeking to fully understand their plan. However, regardless of specific needs or circumstances, all users want to save time and money in the processes of choosing, understanding, and using a health insurance plan.
Currently, information asymmetry between insurance companies and insurees is a source of time and cost inefficiency for the latter, who may be hindered in choosing the best plan or medical care to meet their needs if relevant information about insurance plans is inaccessible (or accessible only through a time-consuming search) or difficult to compare.
In addition, more information does not lead to more empowerment. Often the information available is obscure or unreliable. People feel like they can’t get a consistent, straight answer from their health or insurance providers about what will be covered and how much they will have to pay. There is also choice overload, with the process asking a consumer to make too many complex choices to be strategic. At some point, many consumers just give in and accept what is being told to them by the more powerful other two groups (the insurance and the health providers). They feel like they cannot navigate the process to protect themselves.
There is choice overload and lack of key information
Many insurees do not trust insurance companies to provide full and accurate information or to act in the insurees’ best interests. Information asymmetry is a driving factor in this mistrust. While health insurance literacy is, for some users, a barrier to choosing and getting the most of out of a health insurance plan, even for very literate users, understanding their plan is challenging when information is unavailable, difficult to locate, or out-of-date. For instance, consumers desire more information about in-network healthcare providers, particularly regarding the cost and quality of care.
Pain Points
Some of the main frustrations, at the three key stages
Choosing a Plan stage
The key pain points at this stage are time inefficiency, choice overload, health insurance illiteracy, and difficulty accessing or finding information. According to our user experience interviews, insuree frustration and time inefficiency may result from unfamiliarity with health insurance terminology, as well as difficulty finding and comparing information about different plans’ costs, coverage, and healthcare provider network.
Understanding a Plan stage
The key pain points at this stage are time inefficiency, receiving conflicting answers or vague responses from insurance company representatives, and difficulty accessing or finding information. For example, one user noted, “It’s really frustrating when you talk to different reps and get different answers. I call twice with any question to make sure their answers are the same. If they’re not, I call a third time. It’s crazy to me that someone like me who works within the system still has trouble with it. Insurance is too businesslike and not really trying to help patients. We need advocates within the system!”
Using a Plan stage
The key pain points at this stage are time inefficiency, surprise costs, inaccessible or unresponsive insurance representatives, and information asymmetry (especially regarding costs and the healthcare provider network). Having to choose whether, where, or how to receive treatment without cost information is an oft-cited insuree pain point. Ascertaining the role of referrals in insurance coverage can also cause uncertainty and stress.
Personas of health insurance users
In our user interviews, we learned from proactive and reactive users about their experiences at the stages of choosing a health insurance plan and filing claims.
At the shopping stage, proactive users may be focused on developing their literacy and fully understanding the plans that they are considering. This can be a time-consuming process, especially due to an overwhelming amount of information or plan options. Proactive users are often shopping based on specific needs, such as geographic scope or coverage of particular health conditions.
Reactive users, on the other hand, may have broader comparison concerns, such as finding the cheapest plan or the broadest healthcare provider network. Reactive users may primarily view insurance as a source of “peace of mind.” They therefore may be less motivated to examine all the details of their plan, and may rely on overall ratings or colleagues’ impressions in their decision. For instance, one user who had not yet needed to use his new insurance plan stated, “I will understand it better when I have a real situation.”
At the claims stage, proactive users seek to understand their plan before taking action. They find it difficult and time-consuming to get information about coverage and cost of care from either their insurance company or healthcare provider. Proactive users may even forgo care if costs are uncertain. Some do not trust their insurance company to provide full and accurate information, so proactive users often turn to online sources such as Reddit or Facebook to ask questions, whether due to greater trust or convenience.
For reactive users, especially if they have waited until a medical emergency to look into the specifics of their coverage, the cost of care may come as an unpleasant surprise. However, it is important to note that information asymmetry makes the cost of care obscure for both reactive and proactive users.
People’s Stories & Quotes about health insurance
Whether a proactive or reactive user, nearly every consumer we spoke with sought advice or help from somewhere other than their insurance policy contract or insurance representative when approaching a pain point.
What will it cost me to take my kid to the ER?
One consumer, who described herself as “relatively well-informed,” found the resources provided by her insurer either unhelpful or incomprehensible. When deciding whether to visit urgent care or the ER when her child became sick, she first combed through the “fine print and terms and conditions” of her insurance contract.
Some of the user quotes that illustrated their experience with health insurance
When this exercise proved fruitless, she called her insurer and spoke directly to a representative. Unfortunately, she didn’t feel like her questions were answered and she was no clearer on whether it would be more affordable to visit urgent care rather than the ER. Before resorting to guessing, she visited a neighborhood mom’s Facebook group where she posed the question to the community and asked for their advice. She gained valuable information that was immediately intelligible and that she trusted. Whether the information she received was correct is hard to say, but it allowed her to feel confident in making a decision — something she didn’t feel after combing her contract for information or speaking with her insurance representative.
What should I do about my back?
Another consumer we spoke with found herself in a somewhat similar situation but wound up with a different result. After physical therapy failed to cure her back pain, she decided to undergo surgery, which her doctor assured her would resolve her injury. Her doctor promised to send a pre-authorization form to her insurer. One week before her scheduled surgery, she discovered the doctor’s office had failed to submit the pre-authorization paperwork.
When they finally did, however, the insurance agency told her it was impossible for them to approve the surgery so quickly. She argued for an expedited turnaround, which the insurer agreed to. But, on her way to the surgery, they told her they still hadn’t made a decision. She decided to forgo the surgery and continue enduring the physical pain instead of going through with the surgery without knowing how much of its cost she would be required to cover.
Here, the lack of transparency and the slow process of a seemingly discretionary authorization prevented a patient from seeking medical care she could have used. No Facebook group could have answered this question for her and given her enough confidence that the surgery would be covered to feel comfortable undergoing the surgery.
Who can tell me the real information about this insurance?
A third consumer spoke about different avenues of information gathering he sought beyond his insurer. Whether shopping for insurance or, like the two consumers described above, making decisions about medical care, he found it useful to peruse Google, Facebook, and Reddit and to speak with friends and colleagues. Like the other consumers we spoke with, he found insurers the least informative and most difficult to get a comprehensible answer from. A different consumer told us that she calls her insurer twice whenever she has a question to make sure the first answer she received was correct. If she receives two different answers, she’ll call a third time.
Many of the stories we heard were disheartening and frustrating. The stories described above are only a small sample, but they are representative of the sort of stories we heard during our interviews. In the end, everyone is operating under their own unique circumstances. It boggles the mind that consumers should feel they’ll get better information from a stranger on the internet who knows nothing about the idiosyncrasies of their needs or the contract they have with their insurer than they would by simply calling their insurance representative or reading through their contract of SBC. But, as it is, consumers are operating under a severe information asymmetry with respect to their insurers.
This information asymmetry is not resolved by insurance representatives, insurance contracts, or SBCs. As such, it causes consumers to look elsewhere for help. But the help they receive may not lead them to the best answer. Consumers are inefficiently spending their time gathering information and making cost-inefficient decisions about their healthcare that may have detrimental effects on their own health. Nearly every consumer we spoke with expressed despondency at the fact that nobody was advocating for them from within the system, that they were constantly on their own and information was constantly out of reach.
Agenda for Change Based on Users’ Experiences
The success of insurance marketplaces is related in part to consumers’ ability to understand health insurance contracts and make informed decisions[1]. Competition at the consumer level is likely to reduce prices and improve quality when a sufficient number of consumers make informed decisions[2]. However, consumers can also make suboptimal decisions when faced with overly complex choices[3] or too many alternatives[4].
Moreover, the information asymmetry permeating the health sector represents an obstacle to regulating and promoting competition within this market. In this sense, insurance purchasers who cannot understand health plan offers will find it difficult to make rational decisions regarding the insurance company they wish to contract.
Regarding the problems detected in the private health insurance market, the government has made progress in reforms to reduce information asymmetry and empower consumers to make better decisions. Among these reforms, we can highlight the following:
Hospital Price Transparency
This regulation requires the hospitals operating in the US to provide clear, accessible pricing information online about the items and services they offer. This information but be machine-readable with all items and services and must be displayed in a consumer-friendly format. The main objective is to make it easier for consumers to shop and compare prices across hospitals and estimate the cost of care before going to the hospital.
The government’s major reform efforts have contributed to improving this market. However, future efforts should aim to resolve the pain points consumers face[5].
Summary of Benefits & Coverage
This reform aims to present the consumer a snapshot of the health plan’s costs, benefits, covered health care services, and other essential features. The main objective of this regulation is to help consumers –in the shopping phase — to compare different elements of health benefits and coverage[6].
Metal plans
The Affordable Care Act standardized small-group and individual health insurance policies by creating a “metal” ranking. All the health plans are categorized into Bronze, Silver, Gold, and Platinum metal tiers. Each category offers different ratios of what you will pay and what your health plan will pay for your care.
The government’s significant reform efforts have contributed to improving this market. However, future efforts should aim to resolve the pain points consumers face, such as time inefficiency, choice overload, and lack of health insurance literacy. We believe that technology and computable contracts can be great tools to resolve these pain points we saw in the interviews. The adoption of computable contracting by the insurance companies will create improvements in efficiency for these firms and benefits for consumers[7].
Can Computable Contracts help?
In the second half of our course, we moved from general empathy and exploratory interviews with consumers — to diving into possible solutions.
Computable contracts, in particular, were discussed as a way to improve information transparency, speed of processing, and consumers’ ability to make strategic choices. The students heard from experts at CodeX who are establishing standards and pilots of computable contracts to hear how they might work in the health insurance space. Then they had to develop proposals about human-centered computable contracts to improve people’s health insurance experiences.
In insurance, the product is the contract, different from many other industries. From a consumer perspective, these contracts are often difficult to understand and this information asymmetry between insurers and insurees produces mistrust from customers in insurance companies.
Nora al-Haider made this sketch during an early class
In our research, we identified 4 main consumer pain points with regards to health insurance, which was the focus of our research:
time inefficiency,
choice overload,
information overload, and
lack of health insurance literacy.
What’s a computable contract exactly?
The automation of contracts through computable contracts presents a positive opportunity for both insurance companies and consumers. According to Stanford CodeX, “a computable contract expresses the rights, duties, and processes defined in a contract directly in machine-executable code for querying, analyzing, verifying, and automating contractual obligations.”
Legal rules have a well-defined logical structure that makes them feasible to define in a program. In a simple computable contract, we can program the definitions of events specified in the contract using a set of if-else rules that specify different circumstances, along with the consequences when those events occur.
By putting the understanding of a contract into code, we unlock many new value propositions in using computable contracts. From a consumer perspective, there is improved transparency and understandability of the contract. Through a query of the computable contract, a consumer can understand how their contract applies in different scenarios, such as getting the cost of a procedure that they need to be covered by their insurance company. The computable contract may also have FAQ functions or information visualization that will make it easier for a consumer to understand the terms of their insurance contract. Insurance representatives that interact with the contract, such as sales agents or customer service will also have an easier time answering consumer questions as a result.
One of CodeX & Professor Genesreth’s working prototypes of a computable contract for health insurance
Computable contracts also offer the ability for insurance companies and consumers to increase the customization of their contract and policy with the company. For example, the computable contract can be modular, meaning that a consumer can take elements from different policies that fit their needs the most effectively, and create a customized policy as a result, with little change to the typical operations of the insurance company.
Insurance companies also benefit from computable contracts due to increased efficiency in their operations. Claims processing under computable contracts might only involve a few queries to the computable contract, which will make this faster and lower cost for the company. Insurance companies may also benefit from simplified underwriting due to the automation and improved precision of actuarial calculations. Regulators also benefit from the use of computable contracts, since the more structured nature of computable contracts will support internal oversight and external regulation of insurance companies.
Additionally, computable contracts can unlock new opportunities for innovation in the insurance industry. Through more structured insurance data collection and analysis, insurance companies are able to create more opportunities for the improved effectiveness of data analysis and artificial intelligence tools and research. Insurance companies will also be able to use more thorough analytics about consumer preferences and improved actuarial models to improve their policy design and pricing. Increased interoperability between computable contracts can also help improve reinsurance transactions as well as improve quantifications of risks in pooling and shared risk schemes.
Prototypes for computable contracts in health insurance
This section details our prototypes of insurance products that utilize computable contract technology introduced in the previous section and the responses we received from user testing on these prototypes. These findings are used to inform general takeaways for insurance companies and government agencies for potential next steps.
Based on our understanding of consumer pain points with insurance, our research group created five ideas for prototypes to test, grouped together based on the stages of the user journey: 1) understanding insurance, 2) shopping for a plan, and 3) using the plan.
Prototype: Health Insurance 101
First, for the “Understanding Insurance” stage, we developed a prototype of an educational online training sequence which we call Health Insurance 101. The purpose of this feature is to address the lack of insurance literacy, one of the major pain points for consumers today. Consumers would be able to use this application to complete a series of short videos and quizzes to learn the details of the insurance policy.
Companies could tailor the program to educate the user about specific policies and they could require every policyholder to complete these videos and quizzes at the moment they purchase their coverage and every five years thereafter. Not only would these educational programs provide consumers with valuable basic information about their coverage and how health insurance works more broadly, but it also creates a base level of trust as transparency about policy is given from the start.
Computable contract technology would be valuable in the process of developing these programs as the first step of creating a computable contract is to identify and define domain ontologies, which can be translated into key learning points in Health Insurance 101.
Prototype: Healthcare Map
Next, for the “Shopping for a Plan” stage, we created a prototype of a Healthcare Map that allows people to view healthcare providers near a chosen address and based on insurance plans of interest. Specifically, this application would allow users to discover whether the provider is in- or out-of-network for each insurance plan of interest, the pricing of the provider’s services, and a rating based on quality and safety of care.
Prototype: Best Plan For You quiz
Another prototype we sketched out was a “What’s the best plan for you?” Quiz. After consumers input their demographic information, health information, and insurance needs/wants, this quiz returns a list of insurance plans that fits their needs. Both of these prototypes would simplify the shopping process by resolving the choice overload issue and enabling effortless comparison between plans.
The derivation trees that computable contract technology generates would be an essential part of developing the “What’s the best plan for you?” Quiz, and would make it easy to program the site to give an explanation of why certain plans are recommended. This technology could also be leveraged to create filters for the searching capability on the Healthcare Map since computable contract technology helps organize terms in a machine-readable script.
Prototypes: Cost Calculator & Chatbot
Finally, for the “Using a Plan” stage, we prototyped a Pre-Procedure Cost Calculator and a Logic-Programming based Chatbot.
For the Cost Calculator, consumers are able to fill out a page with information about a possible procedure, and then the tool will automatically inform the user about whether that hypothetical claim would be approved or denied.
If approved, the site will display the amount covered. If denied, it will produce a detailed explanation of why. This cost calculator would empower consumers to make decisions with the full knowledge of what the financial consequence will be.
In the case that consumers have more general questions, we formed the Chatbot prototype to help.
This application could either come in the form of an online chat or a phone call with automated responses. While this technology is already in place for many companies, computable contract technology would improve the bot’s capabilities because the heart of computable contracts is logic programming, which involves breaking down the policies into a set of rules and data, then creating an interpreter that can answer various questions.
The Pre-Procedure Cost Calculator can also be programmed entirely with logic programming as demonstrated by Professor Genereseth’s research. His work with the Codex team demonstrates the feasibility of computable contracts as he was able to create a Hospital Cash Claim form based on Chubb’s hospital cash product.
Results from first round of testing
We presented these five prototypes to six people during user testing sessions and asked them to rank each product based on the prompts: “Would you use this if someone offered it to you?”, “Would this help you get a better outcome with your health insurance?”, and “How easy would this be for you to use & understand?”
These testing sessions were done by recruiting of health insurance consumers from across the US through social media ads, like with our initial empathy interviews. Users were interviewed for around 20 minutes and compensated with $40 gift certificates.
Overall, people reacted enthusiastically to our ideas and the concept of using technology to improve consumer experience with insurance. The average rating for every product is over 4 out of 5.
What Next? Takeaways from Our Prototype Testing
For insurance companies, the user testing and research into the applications of computable contracts suggest that incorporating computable contract technology into a company’s services could streamline and integrate multiple processes.
For example, improving the chatbot would significantly cut down on human resource costs needed for answering people’s questions.
Another key example could be how having a program decipher whether a claim is approved or not would decrease time spent on each claim, allowing more time and money to be spent elsewhere.
For government agencies, our work indicates that requiring insurance companies to make their policies accessible through a computable contract would increase user satisfaction and empowerment.
The feasibility of a government branch mandating companies file machine-readable reports is supported by historical precedent. In 2009, the SEC required “corporations, mutual funds, and credit-rating agencies to report information in eXtensible Business Reporting Language (XBRL), a move that simultaneously reduced the costs of compliance for firms and cut the costs of accessing information for analysts, auditors, investors, and regulators.”
The same concept can be transferred from the finance industry to the insurance industry. Computable contracts then would also make it easier for the government agencies to tell if insurance companies are complying with guidelines because the information becomes easily accessible.
Our partners at CCIO highlighted many of the upcoming changes that could feed into this better future:
Transparency in Coverage requirements, that go into effect on July 2022. Health providers will be required to publicly post their price information, in machine-readable formats. This can be used in computable contract tools to help consumers make smarter choices.
The No Surprises Act (NSA) that will protect people against surprise medical bills. NSA will limit how much providers can charge, and what kinds of authorization are needed to get coverage. This might be useful when combined with a pre-procedure cost calculator.
Computable Contracts and the Law
The myriad potential applications of computable contracts in the health insurance space give rise to several legal issues.
Our insurance stakeholders provided us with the example of a chatbot using computable contracts to communicate policy coverage in layman’s terms. In that case, there was concern that if policy coverage were miscommunicated or misunderstood, the insurance company would expose itself to legal liability. Moreover, computable contracts must comply with data and privacy laws, which pose a particular challenge because they are widely applicable (EU data laws could apply to American insurers if they handle data from EU citizens), varying across many jurisdictions, and rapidly developing. In the following section, we will discuss some of the most important developments and their implications for computable contracts in the health insurance space.
This section will not cover data protection statutes related to health data, such as the Health Insurance Portability and Accountability Act of 1996 (HIPAA). The California Privacy Rights Act of 2020 (CPRA) exempts protected health information (PHI) that is collected by a covered entity and medical information governed by the California Confidentiality of Medical Information Act. However, because the CPRA exempts types of data and not types of entities, peripheral data collected by health insurers are still covered by California data laws.
Developments in Data & Privacy Law
The CPRA is at the forefront of the development of data and privacy laws in the United States. The law created the California Privacy Protection Agency (CPPA) which will begin enforcing the CPRA in July 2023. Major health insurers will almost certainly need to comply with the CPRA for data not covered by medical data laws; any business with more than $25 million in annual gross revenues is covered by the CPRA. Several of the rights granted to consumers in the CPRA were simply carried over from the California Consumer Privacy Act (CCPA) and so will be familiar to insurers. These include the right to: delete personal information, know categories and specific pieces of personal information, opt-out of the sale or sharing of personal information, and non-retaliation.
There are, however, new rights granted to consumers under the CPRA. These rights include rights to correct inaccurate information, limit the use and disclosure of sensitive personal information and opt-out of automated decision-making technology. Computable contracts will need to be able to comply with each of these rights. The right to opt-out of automated decision-making technology was primarily adopted to prevent companies from using machine learning to create consumer profiles, but it could severely limit the effectiveness of computable contracts if consumers are able and choose to exercise it in the computable contract context.
It is unclear to us from a technical standpoint whether these consumer rights will be a hurdle for or benefit of computable contracts. It is possible that computable contracts will make it easier to share information about data collection, make corrections and deletions, and offer opportunities to opt-out of data collection and sharing by better-integrating health insurance information into an insurer’s technology stack. However, it could also be the case that these rights would be difficult to square with computable contracts, in which case back-end use (as opposed to consumer-facing) of computable contracts would be preferable. Back-end applications of computable contracts in contract management would still have a large impact; Bain & Company estimates that improving contract management could save up to 100 basis points (1%) of companies’ revenue. However, it remains to be seen whether this benefit would flow to consumers.
For international insurers, there’s the additional privacy concern of compliance with GDPR and European Union Court of Justice (ECJ) decisions such as Schrems II.In Schrems II, the ECJ invalidated the EU-US Privacy Shield, which had previously allowed for the transfer of personal data from the EU to the US. Though there are currently negotiations for a new iteration of the privacy shield, any similar outcome will be likely to result in another adverse ruling — that is, a Schrems III — from the ECJ because the US seems unlikely to adopt a comprehensive federal privacy bill. As such, international insurers will need to localize their European data in Europe and keep it separate from their US data. This will limit some of the risk aggregation upsides of consolidated insurance data.
Other Legal Implications of Computable Contracts
A separate item for consideration is how judges will understand and apply contract law to computable contracts. On this matter, jurist comprehensibility will be important, especially if the computable contract is closer to code in application than to a natural language embodiment. Again, however, there will likely be a “legalese” counterpart to the computable contract that could alleviate this concern. If there are few operational issues with creating, translating, and managing these counterparts, this will be a viable solution.
That said, there could be a question as to whether electronic agents can even bind their principals through the decisions they make in smart contract code. As the Chamber of Digital Commerce notes, limited contemporary precedence exists on this question. On one hand, the automatic issuance of a tracking number was deemed “an automated, ministerial act” that did not constitute contractual acceptance in Corinthian Pharmaceutical Systems, Inc. v. Lederle Laboratories, 724 F. Supp. 605, 610 (S.D. Ind. 1989). On the other hand, the Tenth Circuit affirmed a district court finding of liability for an insurance company’s computerized reinstatement of an insurance policy, stating that “[a] computer operates only in accordance with the information and directions supplied by its human programmers. If the computer does not think like a man, it is man’s fault.” State Farm Mut. Auto. Ins. Co. v. Bockhorst, 453 F.2d 533 (10th Cir. 1972).
Possible Solutions
A way forward that could meet multiple stakeholders’ interests is a standardized computable contract template — akin to the ISDA Master Agreement for derivatives — for low-complexity, high volume health insurance contracts. The ISDA Master Agreement is a standard document created by the International Swaps and Derivatives Association (ISDA)used to govern over-the-counter (OTC) derivatives (i.e., derivatives traded directly between counterparties and not traded on an exchange). The ISDA Master Agreement standardizes terms for a derivative that can then subsequently be adjusted in a customized schedule. ISDA has been exploring possible applications of computable contracts since 2017. Moreover, since its most recent revision in 2002, the ISDA Master Agreement has developed a corpus of legal decisions that reduce uncertainty over legal matters involved in OTC derivatives.
Standardization would advance CCIIO’s interests by offering consumers fewer and clearer choices that limit cognitive overload and by providing a single template for regulators and watchdog groups to audit. Moreover, it would provide consumers with a body of policy claim decisions based on a similar contract, thereby reducing consumer uncertainty over what is likely to be covered.
Standardization would also advance insurers’ interests by creating a low-risk deployment area to implement and iterate the new technology involved in computable contracts. It would also present an opportunity for jurists and regulators to decide novel legal issues with computable contracts with less financial exposure for insurers.
Future Work
Our research shows that there is significant demand from consumers to improve information access and transparency in their experiences with health insurance, and that computable contracts pose many promising opportunities to alleviate these issues.
Future work that could stem from our research includes further user testing of our prototypes, as well as other computable contract applications, in order to determine which innovations have the most demand.
Another round of user testing might include testing our prototype ideas with a larger and diverse sample size of users to see which ideas are most promising and exciting to consumers. From there, we could create low-fidelity prototypes of the ideas our groups chooses to pursue, and then test various implementations with users to see which they prefer. It would be important for us to test these prototypes with a diverse group of consumers who all have varying insurance needs to ensure that we capture a variety of perspectives in our user research.
Should computable contracts become adopted by the insurance industry, there is also a need to create educational content and materials for judges and other legal professionals to utilize them effectively. One example of this would be training on how a judge can interpret the clauses of a computable contract since this will be quite different to interpret from a contract in document form.
Overall, we believe that there is potential for computable contracts to improve access and transparency in the insurance industry. As a result, insurance companies will benefit from efficiency improvements in their operations, consumers will have an improved experience and trust in insurance, and government agencies will be able to more effectively regulate insurance companies.
[1] Paez. K. et al. “Development of the Health Insurance Literacy Measure (HILM): Conceptualizing and Measuring Consumer Ability to Choose and Use Private Health Insurance”, in Journal of Health Communication, 2014.
[2] Loewenstein, G. et al. “Consumers’ misunderstanding of health insurance”, in Journal of Health Economics, 2013.
[3] Scitovsky, T. “Ignorance as a source of oligopoly power”, in Am. Econ. Rev. 40, 1950, 48–53.
[4] See Shaller, D. “Consumers in Health Care: The Burden of Choice”, Oakland, CA: California HealthCare Foundation, 2005; Wood, S., et al. “Numeracy and Medicare Part D: The Importance of Choice and Literacy for Numbers in Optimizing Decision Making for Medicare’s Prescription Drug Program” in Psychology and Aging, 2011, 295–307.
[5] See Centers for Medicare & Medicaid Services. Available online.
[6] See Health Insurance Marketplace, Understanding the Summary of Benefits and Coverage (SBC) Fast Facts for Assisters. Available online.
[7] See CodeX, Computable Contracts and Insurance: An Introduction. Available online.
LIST problem codes are standard ways to describe legal issues. How can you use them to make legal help better?
1. We need standard codes for legal problems.
There’s lots of different words we can use to describe the same legal problem. Is this thing an unlawful detainer, an eviction action, a landlord-tenant dispute, or getting kicked out of your house? These words come from legal jargon, different jurisdictions’ terminology, and people’s everyday language around the law.
This is a problem for building good legal help online.
To actually, efficiently connect people to help that fits their problem, we need standardized ways of referring to what these problems are. Taxonomy codes are one way to do this. If we have a standard, encoded term from a central taxonomy for each legal problem — then we can use this term to be standardized across websites, apps, and jurisdictions. Even if we use different words (eviction, u.d., kicked out) to call these problems, if we’re always using the same term (HO-02–00–00–00) when we talk about this problem online.
Our lab has spent several years, and with the support of the Pew Charitable Trusts and the Legal Services Corporation, to build this standard taxonomy of legal problem codes. It’s called LIST, the Legal Issues Taxonomy.
So how do you actually use these taxonomy codes?
How do you make these codes work for you and your users?
2. Web administrators can tag their help resources with the LIST codes.
If you run a website that offers legal help — like a legal aid site, a law library, a court help center, or otherwise — you can use these LIST codes to make it easier for people to find your help resources. And you can make it easier for other help providers to link to your resources.
The best way to use the LIST taxonomy codes is to put them in Schema.org markup, that describe your websites’ topics to search engines. You can do that by using this Schema markup creator tool that our Lab has created.
You can make this Schema markup, and then paste it into your website’s header. This markup will describe your legal help organization and the issue areas that you cover. The form automatically puts the right LIST code in for the issue area you select on the page.
Or, you can manually create your own Schema markup using LIST codes. You can use the Schema term KnowsAbout, and then populate it with the LIST codes that represent the legal problems your organization can help people with.
3. App & bot developers can use LIST codes to encode people’s inputs and their responses.
If you build bots, conversational agents, and other apps that go back-and-forth with users, then the LIST taxonomy codes can help you tag what people are asking for help with. And you can similarly encode the resources and links you’re offering to your users.
For example, our Lab’s Eviction Help Bot can spot people’s legal problems around possible evictions and landlord-tenant. It does this by running people’s posts on the Reddit/LegalAdvice forum through the SPOT tool from Suffolk LIT Lab.
We have SPOT read the post and then determines if one of the LIST legal problem codes seems to be present. If a LIST problem code around eviction probably applies, then the Eviction Help Bot replies to that Reddit-user with an automatic message about websites that could help them.
When we were building that bot, we programmed which LIST problem codes the bot should be sensitive to. Other bot- or agent-developers can use the LIST codes similarly.
Set up SPOT account and connection. You can set up an account and a way for your tool to make calls to SPOT through its API,
Use SPOT to make sense of your users’ text: You pass a piece of user-generated text (a search query, a paragraph description of a problem, a transcription of an intake call) over for SPOT to categorize, and then
Get the LIST problem codes back from SPOT: You have SPOT return the LIST issue codes that seem to be present.
Have your tool use the codes to reply intelligently: You have your bot or agent respond accordingly. You have automated responses or links associated with certain LIST issue codes. If eviction issue codes are returned, then have the bot reply with links to eviction help resources. If divorce issue codes are returned, then you can have an automatic message on the divorce process.
4. Referral link to other groups’ webpages & contacts based on their LIST-encoded expertise
This last use case is a more ambitious one. It requires multiple legal help groups to coordinate using the LIST problem codes.
Let’s say that you run a lawyer referral system, and want to better match people calling in to a lawyer that can help them with a specific problem.
Or let’s say that you run a legal help website, and want to be able to direct visitors to the right online resources for the problem they have. Maybe your group’s website has self-help materials on debt, wage theft, and repossession. But you don’t have many materials on protective orders, divorce, custody, or other family law matters.
And maybe you serve clients in southern Ohio, but not in central or northern Ohio (or from other states or countries). You don’t want to be giving incorrect legal procedure guidance to visitors. You want to make sure they find local-jurisdiction help.
LIST codes could help you make better hand-offs for your web visitors or people calling into your referral line. If you have used LIST to encode legal help websites’ expertise topics, or lawyers’ expertise areas, then you can easily find the right next step for the person.
If other legal help groups are using LIST codes to describe the issues they have resources on, and the jurisdictions they serve — then you could use this information to tell your visitor which website they should be visiting to get issue- and jurisdiction-correct help.
This would require making a referral database system using the LIST codes and jurisdiction codes, and then having a search/input function on your website. When your visitor searches for a certain issue/location, or inputs a story about an issue/location, then your site can draw from the referral database to pass the visitor off to the best website for them.
We haven’t yet built this kind of intelligent referral system — but we know others are starting to. This can include through steps like:
Having lawyers or legal groups all report what issue areas they can help with, or that they have self-help resources on. Ideally, this would be on a structured form, with a drop-down or multiple choice list of issue area options. These submissions should all be encoded with standard LIST problem codes. Then this will make it easier to search for and identify which lawyers/websites could be good matches for a specific person.
Creating a master-list of legal help websites, and which URL pages have help for certain issue areas. This entails collecting a database/spreadsheet of main website pages, as well as specific sub-pages that have help for certain problem areas. Each page’s listing should have fields that describe the LIST problem codes present on the page, and the jurisdiction code for what it applies to. Then people and tech tools can draw from this master-list to find the local, issue-specific page to refer people to. You can see the start of such a master-list here.
Do you have other use cases for using LIST problem codes, or other taxonomies in your justice innovation work?
Please let us know! We believe in the power of standards and coordination.
Our Better Legal Internet project at Stanford is all about one thing: making it easier for people to get free legal help, especially online.
Search matters for legal help
People have life problems where legal aid might help
We know more people are looking on the Internet for answers to their life problems. This includes searches for ‘legal’ or ‘justiciable’ problems — in which a person might be able to use legal aid or courts to help them deal with it.
Some examples of legal life problems are:
When your landlord is harassing you by stopping into your home unannounced, or when your landlord refuses to make repairs in your rental
When you are getting threatening calls from someone trying to collect money they say you owe, for past-due medical bills
When you want to see if you can get a past misdemeanor cleared from your record, so future employers or landlords won’t see it
When you are worried about a partner’s abuse towards you and your kids, and you think you might need a restraining order to protect yourself
When a contractor you hired to fix your roof isn’t doing the work he promised and isn’t returning your calls
Life Problems sometimes = Legal Problems
These are situations where a person could try to talk with the other person to resolve the problem. Or they could ignore it, and hope it resolves on their own. Or, they could reach out to see if they have rights, protections, or options to use the legal system to get a resolution.
This third option, of using the legal system, ideally will help a person use the law to get the situation resolved with a good social outcome — stopping bad landlord behavior, stopping the debt collector harassment, clearing your record, protecting you from harassment, and holding a contractor accountable.
Legal Aid websites aren’t showing up on search
Every area of the US has at least one legal aid group or court services center to help people with these civil justice problems, and they do so for free. And these legal aid groups and court centers all have websites to help people connect with them.
But the problem is…
When people search online for problems like the ones above, many don’t see the legal aid or court websites. Our Lab has been auditing what Google shows when people search for queries around eviction, domestic violence, debt collection, and contractor fraud. (We’ll be publishing these audits soon. Stay tuned!)
What should people see here?
What shows up most often are commercial websites, not public interest ones. And when there are .org or .gov sites showing up, they are mainly national sites — not local legal aid or court websites. Rarely are people being shown their local, free legal help groups.
So then the question is: how do we help improve the search placement of legal aid groups & court self-help centers? How do we increase the likelihood that people will find these free, non-profit services online?
Schema.org Markup as a way to improve public interest SEO
Search Engine Optimization (or SEO) may be a hot topic in commercial websites, but not necessarily among government and non-profit agencies. SEO is a group of ever-evolving techniques to get a site’s pages to place higher on Google, Bing, Siri, Duck Duck Go, and other searches.
Some classic SEO techniques include having other reputable sites link to yours, having content that matches keywords people are searching for, and making one’s site mobile-friendly and fast-loading. Search engine algorithms will likely give more authority to your site when you use these SEO techniques.
Our group was interested in one particular, newer technique: Schema.org markup.
What is Schema markup and why should legal help websites care?
Schema.org markup is code to put on your website’s backend, which tells search engines important information about who they should show your website to. It’s a way any website can better inform Google, Apple, Bing, Yandex, or Duck Duck Go what content they have, and what kinds of searchers to send them.
Schema.org markup
The Schema.org community is a non-profit group (founded originally by leading search engine companies, to improve how structured data is provided and used by search engines’ crawlers). Schema.org defines the various terms and structures that organizations can use to mark up their websites. The markup represents information about some key areas that apply to legal aid groups and courts:
Organizational Details: Who your organization is, and what makes you authoritative on certain topics
Issue Areas: What kinds of problems and questions you can help people with
Jurisdictions: What jurisdictions and geographic areas you serve
Demographic Groups: What specific demographics of people you serve
Services and Events: What specific hotlines, intake channels, clinics, and other events you offer
Legal help websites can use the standard Schema.org markup code to represent this information in ways that search engines can understand automatically. This markup code should improve how often a website is shown to people asking about legal issues, in target jurisdictions and demographics.
Our team worked with legal aid groups, legal technologists, and community members from around the country to develop a protocol of how legal aid groups and courts can use Schema.org markup on their websites. This is important because Schema.org itself has thousands of terms — and it can be very overwhelming to decide how to represent an organization and its services. Our protocol provides a standard for how to do this.
You can see our existing example Legal Help Schema.org markup for various legal aid groups at our Github repository here. We will be publishing a tool soon for groups to create their own markup easily. Stay tuned!
Okay, so let’s say that you’re interested in what this markup is, and if it can benefit your organization + users.
The next step is understanding just enough about it, that you can work with your website administrators to get it going on your site.
That means it’s good to get conversant in structured data on the web. You don’t have to become an expert technologist or SEO master — but you’ll understand more about how the Internet and search work, especially to connect to your audience better.
Legal Help Schema is a standard set of tags that can be applied to content on a website. Like html, it will tell applications how to understand the natural-language text — making it clear what this text means not just to humans but also to machines.
Schema tags can be used by anyone (with basic technical skills) can make their existing website content more easily searchable and understandable to other applications — in particular search engines. It integrates into the wider Schema.org standards, of how to markup site content, so that search engines can discover and display it more effectively.
Legal Help Schema is being created specifically for the types of content on legal help sites. It tags up particular legal issues; what jurisdictions the information concerns; what types of procedures it refers to; and what service provider contact info, fees involved, and eligibility criteria apply.
The Schema tags can be used by courts, self-help centers, non-profits, clinics, and other online legal help providers to improve the machine readability of the content on their site.
Our team has been integrating legal help categories from the LIST taxonomy Database, to tag legal help topics and materials online. We can use Schema.org markup to tell the search engines what legal issues are being talked about, by referring to LIST’s standard list of issue codes.
Not only should court and official material appear higher in the search results, but it may also be presented in ‘smart snippets’ with excerpts and priority provided to people directly on the search results page. The tagging will tell how search engines can best display legal help information, using smart snippets, excerpted bullet-point lists, form and fee previews, contact information for service providers, and other priority displays.
Also, it will ensure that users are directed to the correct jurisdiction of material.
How medical queries are being answered directly with rich snippets and knowledge panels on Google
Just as the Mayo Clinic and other medical experts created a standard Markup language for their online content, our team is working with Schema.org to create a standard markup schema for legal procedures and service information.
We’re hoping that in the next few years, we’ll have great legal help results showing up on search engines, and being spoken back by Siri or Alexa. Please be in touch if your org wants to work on this with us!
A speculative mockup of how standard eviction results could look like on Google Search results page